In the last few blogs, we discussed how Kubernetes has become a game-changer in the adoption of cloud computing and how you can get up to speed with it. We also discussed how Kubernetes differs from other orchestration tools like Docker Swarm and how you can make the right choice for your use case.
In the last blog, we spoke about the main components of Kubernetes architecture and how you can set up one in your local infrastructure. In this blog, we will discuss an important concept of Kubernetes workloads and how it will help you design your Kubernetes infrastructure better.
Let’s get started.
Kubernetes workload
A workload is a component that runs inside a set of pods. A Pod, in itself, is a set of containers. Pods are created and destroyed as needed to manage the traffic by using controllers.
Controllers monitor the state of Kubernetes resources and are responsible for keeping them in the desired state. If the current state is different from the desired state, the controller would make the necessary requests to change the state.
Workload resources configure the controller to ensure correct pods are running and match the desired state. So, we do not manage each Pod individually but use “workload resources” to manage a set of pods. The workload resources configure the controllers to ensure the desired state is maintained.
There are many types of workload resources available in Kubernetes. Each is described in a YAML file that also specifies the kind of workload resource it is. You can run any of the YAML files describing the workload resource with a kubectl apply command:
kubectl apply -f <yaml file>
Let’s have a brief look at the most important workload resources in Kubernetes and how they are defined within a YAML file.
Workload Resources
ReplicaSet
ReplicaSet is used to ensure the continuous availability of Pods. It specifies the number of replicas of the Pods that should exist at all times. Here is how a ReplicaSet is defined in a YAML.
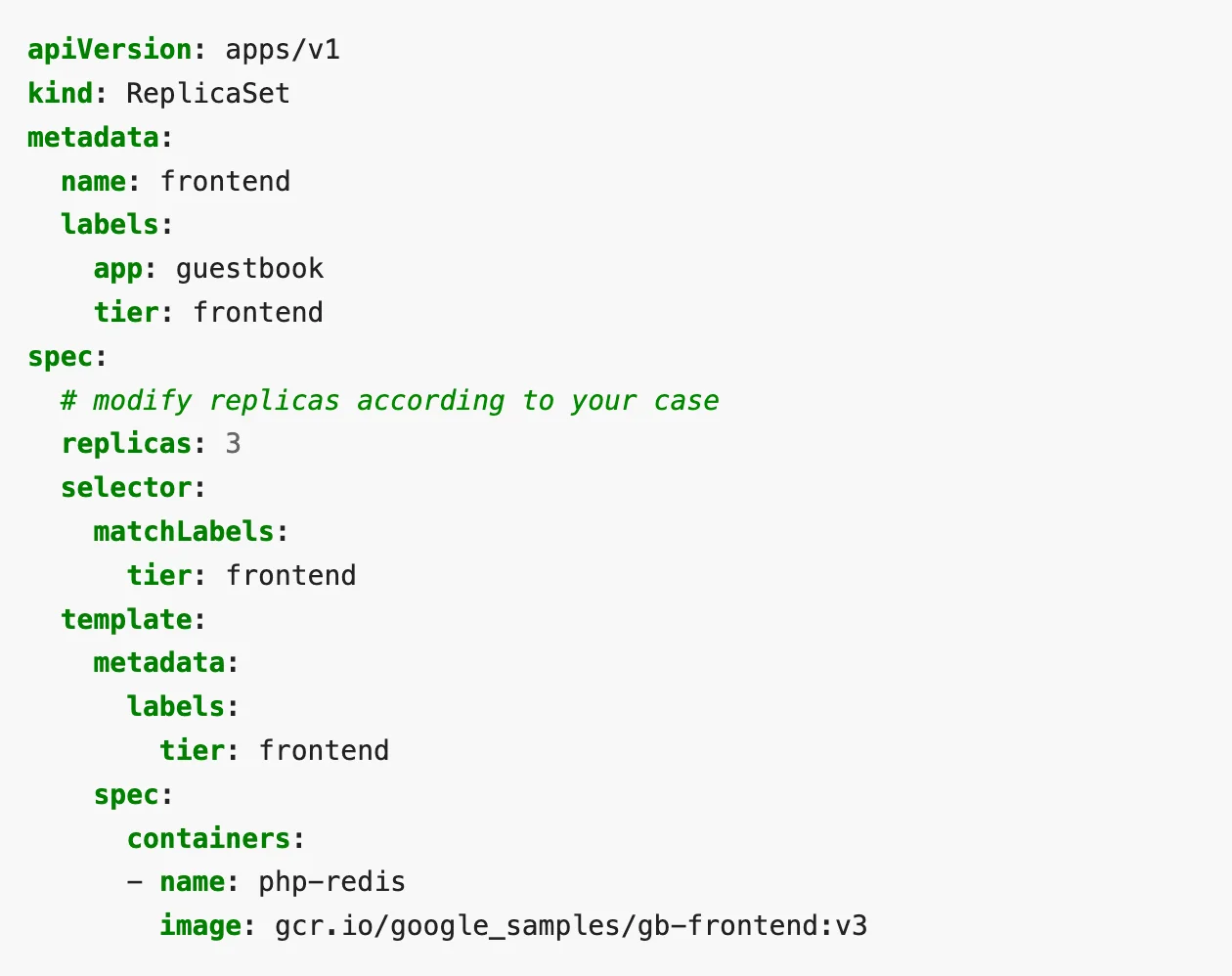
A ReplicaSet YAML is identified with the field “kind:” in the file. The .spec.replicas field mentions the number of replicas of the Pod the set must have. The matchLabels within .spec.selector specifies the way to identify the Pods the ReplicaSet can acquire. The Pod template is mentioned under .spec.template. ReplicaSet uses the description in the Pod template to create new Pods.
You can read more about ReplicaSet in the Kubernetes docs.
Deployment
A Deployment will have a description of the desired state of the Pods and ReplicaSets. The Deployment Controller then picks the actual state and compares with the desired state. If the two states are different, it makes the changes. Deployments can create new Pods, ReplicaSets and even take resources from other existing Deployments.
Here is a sample Deployment called “nginx-deployment” that creates a ReplicaSet with 3 nginx Pods.
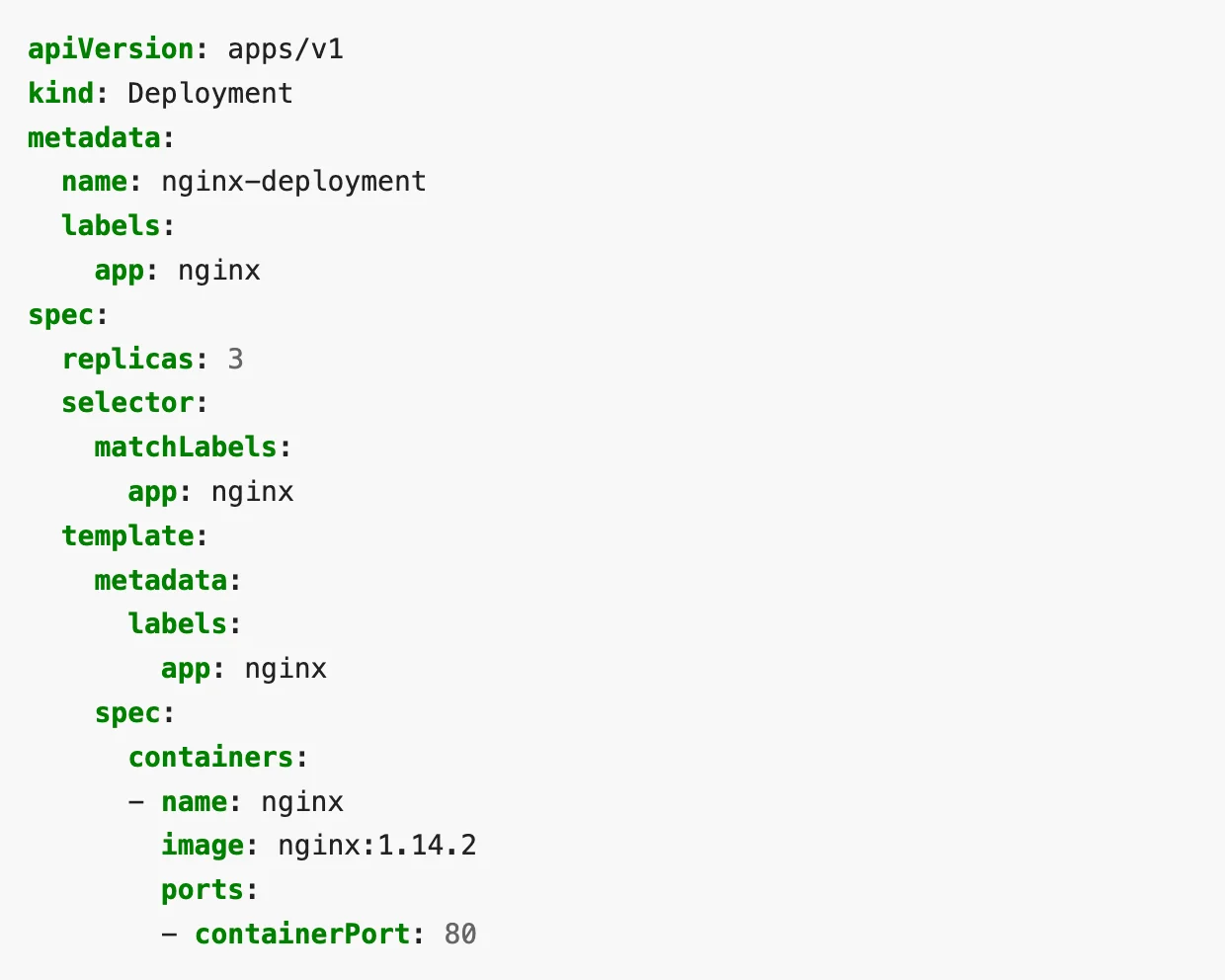
The field .spec.selector.matchLabels.app tells how the ReplicaSets will know which Pods to manage. The Pods for this Deployment will have the label “app: nginx”.
Further below, the label for the Pod template is defined under .spec.template.metadata.labels. The spec for the container is also defined in the template under .spec.template.spec.containers. It mentions the container to run nginx image of version 1.14.2 at port 80 from the Docker Hub.
You can read more about Deployments in the Kubernetes docs.
A Deployment file is identified by the value in the field “kind:” as Deployment. In the file above, field .spec.replicas mentions the number of nginx pods to be deployed.
Should we use ReplicaSet or Deployment?
A ReplicaSet is used to ensure that a specified number of Pods are always running at any point in time. A Deployment is a level higher than ReplicaSet. A Deployment can manage ReplicaSets and describe Pods within it.
Since Deployment abstracts ReplicaSet further, it is a better choice unless the use case requires a custom update orchestration. In most cases, a Deployment is a better choice as a workload resource to define the application in the spec section.
StatefulSet
In some containerized applications, there may be a need to use storage volumes to provide persistence for the workload. A StatefulSet maintains an identity for each Pod. This means the Pods, although made from the same spec are not interchangeable. The persistent identifier is maintained even when rescheduled.
If any of the Pods fail in a StatefulSet, the identifier remains the same and that makes it easier to match existing storage volume with the new Pod that replaces the failed one. In this way, a StatefulSet is used to manage stateful applications. It can manage deployment and scaling of a set of Pods while maintaining the uniqueness of each Pod.
Here is a sample YAML file describing a StatefulSet:

In the above example, a StatefulSet web is defined with 3 replicas of a Pod containing nginx containers. The field volumeClaimTemplates will provide the stable storage details.
You can read more about StatefulSet in the official docs.
DeamonSet
This workload resource is used to ensure that a certain set of Nodes will run a copy of a specific Pod. With a DaemonSet, once a node is added to a cluster, the Pods of the DaemonSet are added to them. Similarly, when a node or the DaemonSet is removed, the Pods are also removed.
This workload resource is very useful to run monitoring and logging daemon processes on every node in a cluster. Since the Pods in the DaemonSet are automatically created within every new node, the DaemonSet can also be used to run cluster storage daemon.
Here is an example of a DaemonSet definition:
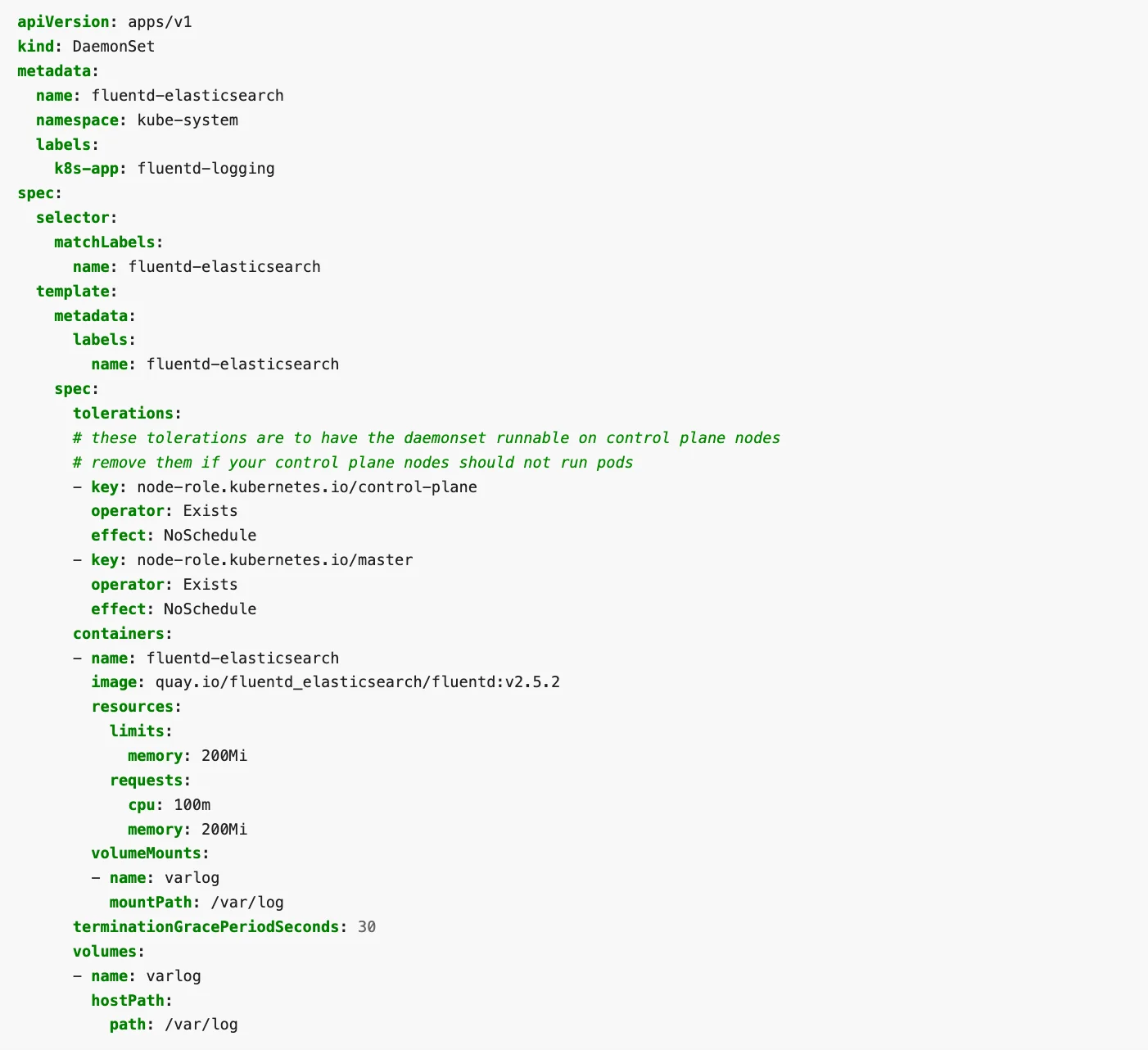
In the above example, containers running Docker image “fluentd-elasticsearch” in created in each Pod, which is replicated on every node in the cluster.
You can read more about DaemonSet in the official documentation here.
Job
In some use cases, you may need Pods to successfully complete a task a specified number of times. A Job tracks the progress of Pods with successful completions. Once a set number of successful completions is reached, the Job is tagged as complete.
If any of the Pods fail, it will retry execution until the specified number of them is successfully completed. Deleting a Job will remove the Pods it created. Suspending one will delete the active Pods and re-create them when the Job is resumed again.
Here is a sample Job described in YAML:
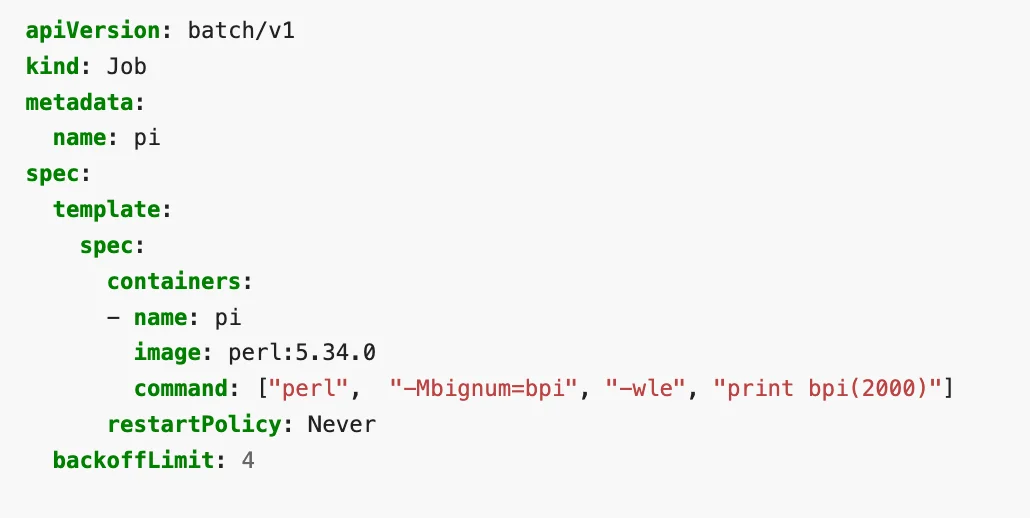
The above example computes and prints the value of pi to 2000 places. You can read more about jobs here.
CronJob
A CronJob is a Job on a recurring schedule. It is similar to an entry in a crontab file. Based on the mentioned schedule, the job will run periodically.
CronJobs are very useful in executing tasks that need to be done periodically in a Kubernetes cluster. So, processes like backups, report generation etc. are perfect for CronJob.
To create a CronJob, you need to use a scheduling syntax as in a crontab file. Here is a short tutorial on the scheduling syntax:
Each “* or number” define the point in time, when the CronJob must run.
CronJob syntax

A sample CronJob workload YAML would look as follows:

The above example prints the current date and the sentence “Hello from the Kubernetes cluster”.
Custom Resource Definitions
If any of the standard workload resources do not serve your purpose, there is a way to create your own Custom Resource Definition (CRD). Custom resources extend the Kubernetes API, and once installed, users can create its objects like other workload resources.
Custom resources can be used with custom controllers. With custom controllers, Kubernetes API can be extended to be used for specific domain applications.
You can learn more about Custom Resource Definitions in the official Kubernetes docs here.
Embrace the Taikun advantage
Defining the right workload resources in YAML files can get complex very quickly. What you need is a way to manage all this complexity through an intuitive dashboard that automatically takes care of the right workload resource you would need.
Instead of a large team of engineers working to set the right configuration in your Kubernetes setup, you need a powerful, intuitive tool that can act as your Kubernetes engineer. This is where Taikun can help.
Taikun is the answer to handle everything Kubernetes. Taikun provides a fairly intuitive dashboard that allows you to monitor and manage your Kubernetes setup. It works across multiple cloud platforms – private, public, or hybrid.
It works with all major cloud providers like AWS, Azure, Google Cloud, and OpenShift. It helps teams to manage complex cloud infrastructures without worrying about how the internals work.