



According to a 2021 CNCF survey, 96% of all companies surveyed are either using or evaluating Kubernetes in their infrastructure.
As you get comfortable using containers for your software deployment (read more about containers in our ultimate guide), you will soon require a tool to manage container deployments and configuration dynamically. This is where Kubernetes comes into the picture. Kubernetes is one of the most popular container orchestration tools. As the CTO for CNCF says, Kubernetes has now become “utterly ubiquitous”.
In this guide, you will learn everything you need to get started with Kubernetes. Let’s start with understanding what makes Kubernetes special.
Kubernetes and Cloud computing
Kubernetes is an open-source tool that can help in automating deployments, scaling, and in general, managing containerized applications. This means as your cloud application grows beyond a single container, Kubernetes (also called K8s) will group containers together into logical units and abstract them for easier management.
Kubernetes started as an internal project in Google but has now become a must-have in any cloud deployment framework. Kubernetes is great for development teams as it can manage the underlying container infrastructure automatically.
This helps developers not only automate deployment in the cloud but also perform rolling updates of cloud-native applications. Kubernetes can detect service downtimes in containers and automatically restart services if a process crashes within a container. This self-healing capability allows Kubernetes to manage applications and give near-zero downtimes.
Kubernetes being open-source, gives the freedom to be used on private, public, or hybrid cloud effortlessly. It also has time-tested scaling capabilities that allow companies like Google to manage billions of containers in their cloud infrastructure. This flexibility to manage complex use cases with containers allow Kubernetes to work both locally and globally at any scale.
You can read more about why Kubernetes is an integral part of the cloud computing future in our blog here. Kubernetes is not the only container orchestration tool in the market. Docker Swarm is another popular tool. Let’s see how they are different.
Kubernetes vs. Docker Swarm
Docker Swarm is another open-source container orchestration tool like Kubernetes. It is native to the Docker ecosystem and supports orchestrating docker containers.
Docker Swarm is quite straightforward to install and great when working with Docker containers. It has automatic load balancing and has Swarm APIs to interact with the clusters.
Unlike Kubernetes, Docker Swarm is tied closely to the Docker ecosystem and hence has limited functionality compared to a Kubernetes system.
Kubernetes also has greater capability to build complex clusters. Docker Swarm, on the other hand, is more lightweight and easier to install compared to Kubernetes.
You can read more about Docker Swarm and how it is different from Kubernetes in our blog here.
Let’s now try and understand basic Kubernetes architecture and some of the basic terminologies within it.
Understanding Kubernetes architecture
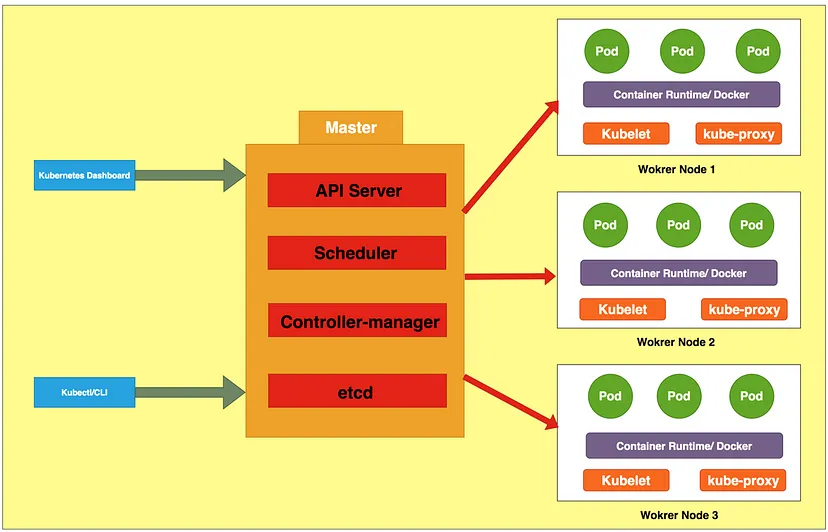
Pod & ReplicaSet
To understand Kubernetes architecture, we need to understand the concept of a pod. A pod is a group of containers that are closely connected to each other. They share a network and storage. They are also deployed and managed as a single unit.
The multiple containers in a pod allow flexibility and scalability for the application the containers within are supporting. Even if one container goes down, there are other ones in the pod that keep the application running.
A group of pods deployed for an application is called a ReplicaSet.
Nodes & Cluster
Nodes are physical or virtual machines that contain all the required services running to host pods. A Kubernetes architecture consists of a Master node and many worker nodes. A master node contains some additional services that help control worker nodes and manage workload across pods.
Multiple nodes running together to run a containerized application is called a cluster.
Deployments
A deployment is a declarative state of a pod. While deploying any application on Kubernetes architecture, the “desired state” of the pods is declared. In the backend, the Kubernetes engine handles the actual deployment tasks to ensure the desired state is reached.
kubelet
Kubelet is a small service that resides on each worker node. It is responsible for applying the “desired state” on the containers in the node. So, a kubelet can create, update and destroy containers on a Kubernetes node.
kube-proxy
Kube-proxy connects each node and pods within the nodes to the Kubernetes network. It maintains network rules on the nodes, which allow network communication between the pods and the rest of the network.
etcd
Kubernetes has data (for eg. its configuration data, its state, and its metadata) that needs to be stored in a distributed data store. Etcd serves this purpose. Etcd allows any of the nodes in the cluster to read or write data into it.
etcd is a part of the master node.
kube-controller-manager
This daemon in the master node is responsible for monitoring the state of the Kubernetes cluster. If the current state is different from the desired state, the controller-manager sends instructions to shift the cluster to the desired state.
The instructions are sent via the apiserver to the kubelet service running in each node.
kube-scheduler
In the master node, another daemon called the scheduler is responsible for assigning pods to different worker nodes. It determines which nodes are valid placements for each pod and binds the pod to the appropriate node.
kube-apiserver
The API server is the front end that helps all components in Kubernetes architecture to interact with each other. The apiserver processes REST operations. It also validates and configures data for all api objects in the network like pods, services and others.
kubectl
Kubectl is the command line tool to run commands on Kubernetes clusters. Kubectl commands can deploy applications, manage clusters and view logs. Here is a sample output of a kubectl command.
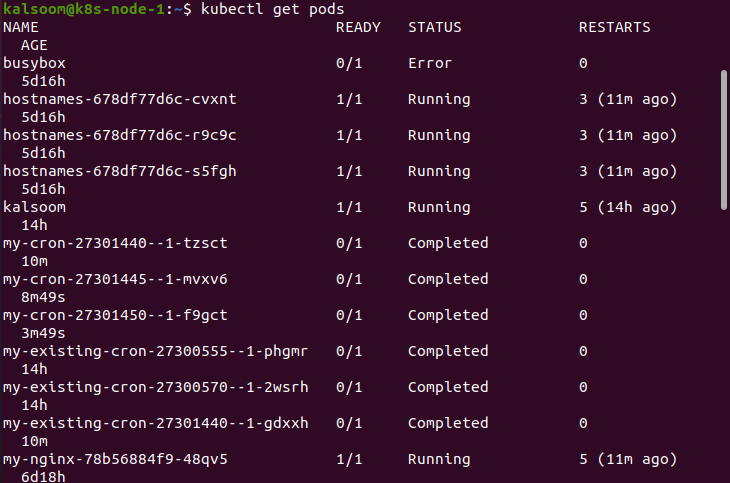
You can learn more about kubectl from our blog Managing Kubernetes with Kubectl.
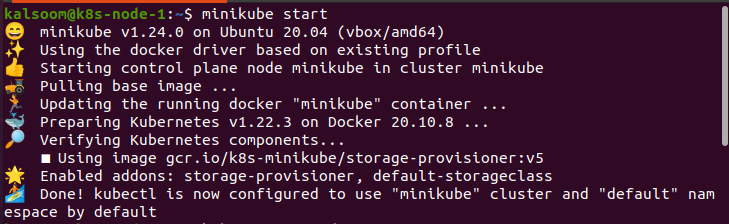
minikube
Minikube is a tool that helps you run Kubernetes locally on a single node. This helps a lot in testing and development work.
Here is a sample minikube command. You can read more about minikube from their official docs.
These are the most important things in a Kubernetes architecture. If you wish to know more about Kubernetes architecture, read our detailed blog Introducing Kubernetes Architecture – From Zero to Deployment.
Kubernetes workloads
Kubernetes workload refers to the application that is running on Kubernetes pods. These are managed by controllers to ensure the pods are in the desired state as defined in the deployments.
We talk more about Kubernetes workloads in our blog Kubernetes Workloads – Everything You Need to Get Started.
Kubernetes Namespaces
Namespaces help divide a Kubernetes cluster into logical units. This can help achieve granular control over different cluster resources. There are many useful instances where namespaces can help. For example, namespaces can help apply specific policies to certain parts of the cluster.
Namespaces are also very useful to define RBACs (Role-based access control). You can define different roles and then assign to a namespace. This is called role binding. This can help in improving the security of the Kubernetes cluster.
There are two types of namespaces in Kubernetes: system namespaces and custom namespaces. In any new cluster, Kubernetes automatically creates the following system namespaces:
- default
- kube-node-lease,
- kube-public, and
- kube-system
We have a detailed blog on Kubernetes Namespaces here.
Running applications on Kubernetes
A basic deployment in Kubernetes is done by defining the desired state in a YAML file. A sample YAML would look as follows:
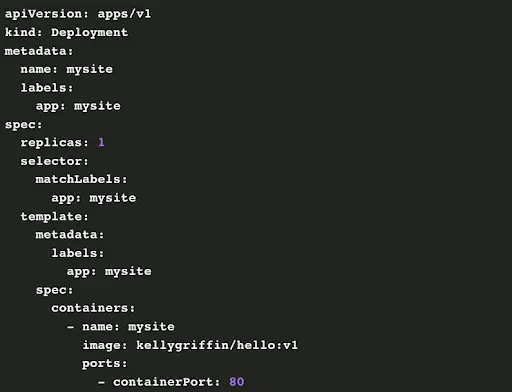
In this YAML file, a Kubernetes deployment object is created with the name mysite. The tag “kind:” and “metadata:” defines that. The object also uses a label “app: mysite” to refer to this object.
The line “replicas:” define the number of ReplicaSets that the cluster must create for hosting the application. If at any point any pod fails, the Kubernetes controller will automatically instruct the kubelet to create from pods to reach the desired state.
The pod defined in this YAML file is created from an existing template. The “spec:” line mentions the template to be used for creating the containers within the pod. In this case, it is “kellygriffin/hello:v1” container. Further, the spec also details that this container will listen on port 80.
With the YAML file ready, the application can be deployed and run with a kubectl command. Say the YAML file is saved as “testdeploy.yaml”, the command to run the cluster would be as follows:

You can learn more about deploying and running a containerized application on Kubernetes from our blogs here and here.
Taikun – A Kubernetes management tool
Taikun is a container orchestration tool that works across private, public, and hybrid cloud setups and helps you have a centralized management dashboard for all your Kubernetes deployments.
It not only automates your Kubernetes deployments but also provides excellent monitoring capabilities from a central dashboard. It works with all of the major cloud providers like Google Cloud, Microsoft Azure, Amazon AWS, and RedHat OpenShift.
